

La haute disponibilité de l’infrastructure informatique est un levier stratégique pour prévenir les crises, optimiser la productivité et renforcer la compétitivité des entreprises.
Qu’est-ce que la haute disponibilité ?
La haute disponibilité (High Availability), c’est la capacité d’un système informatique à fonctionner sans interruption, ou avec un temps d’arrêt minimal, malgré des pannes matérielles, logicielles ou des erreurs humaines. L’objectif est d’assurer une continuité de service pour que les utilisateurs ne subissent pas les conséquences des problèmes techniques.
Chaque minute d’indisponibilité a des répercussions néfastes pour l’entreprise.
Cependant, comment garantir qu’une infrastructure reste opérationnelle 24/7 ? Comment assurer la haute disponibilité même en cas de panne ou de défaillance ?
Les piliers de la haute disponibilité
Afin d’assurer une haute disponibilité des SI, plusieurs dimensions doivent être prises en compte : la redondance, la sauvegarde, la surveillance, le plan de reprise d’activité et l’équilibrage des charges (voir détail ci-dessous) :
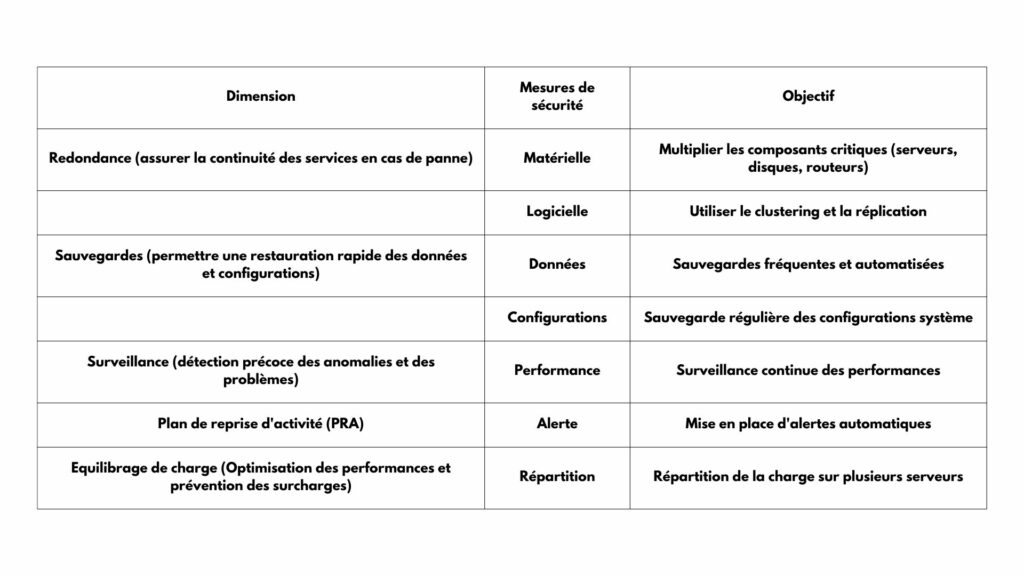

Redondance des composants
Pour garantir et assurer la haute disponibilité, il est important de créer des redondances à différents niveaux de votre infrastructure. Que ce soit au niveau des serveurs, des routeurs ou des bases de données, chaque composant doit pouvoir être remplacé en cas de panne.

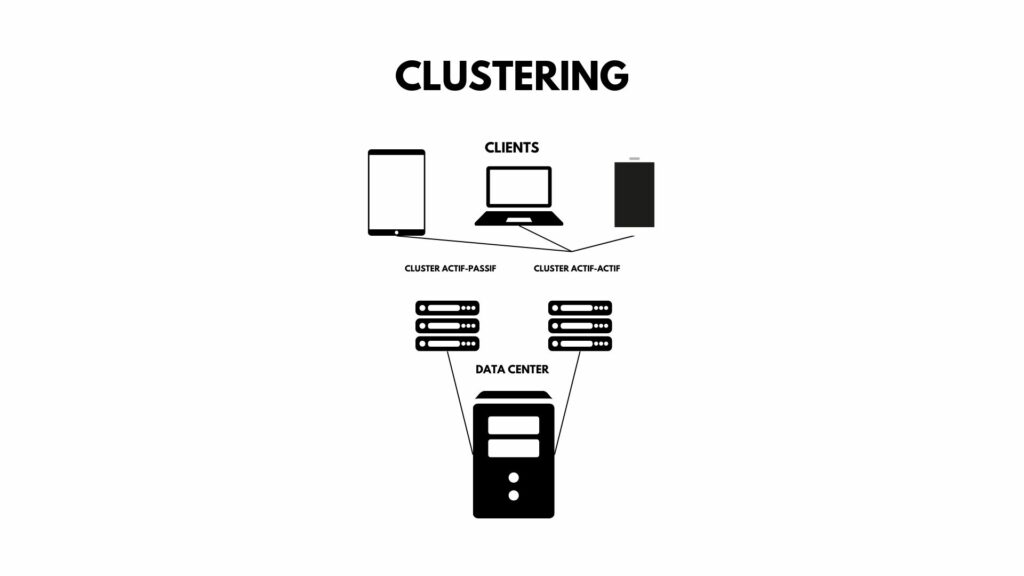
Clustering
Le clustering consiste à connecter plusieurs serveurs pour qu’ils fonctionnent ensemble comme un seul système. En cas de défaillance d’un serveur, un autre serveur peut prendre le relais immédiatement. Cette approche permet d’assurer une continuité d’activité et d’optimiser la résilience de l’infrastructure.
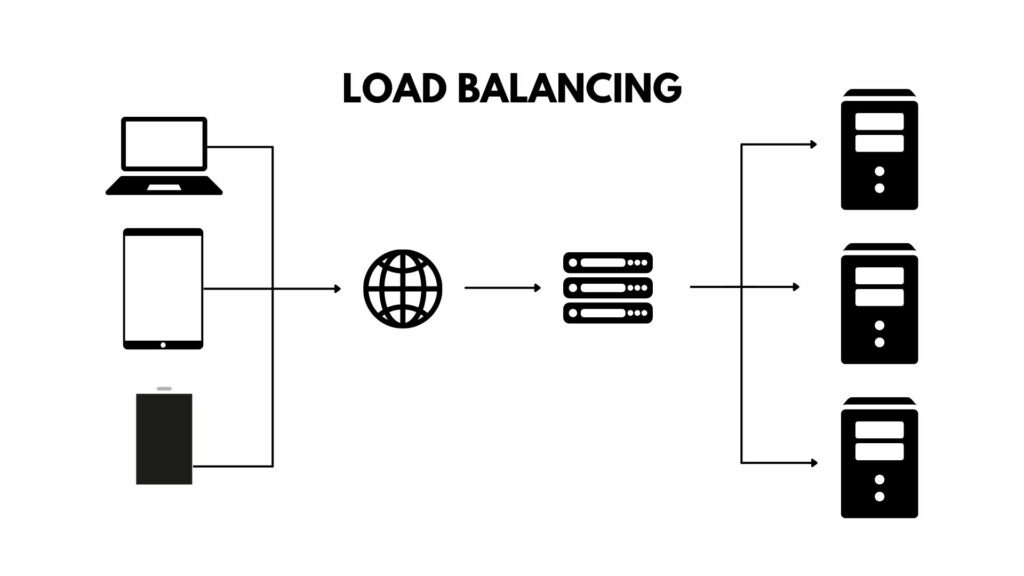
Répartition de charge (Load Balancing)
Le load balancing consiste à répartir le trafic ou la charge de travail entre plusieurs serveurs, pour éviter qu’il ne soit surchargé et risque de tomber en panne. Souvent matériels ou logiciels, ils sont configurés pour surveiller la santé des serveurs backend. Si l’un d’eux tombe en panne, le load balancer redirige automatiquement le trafic vers les autres serveurs disponibles et tout reste fluide et sans interruption.
La surveillance proactive d’une infrastructure permet d’identifier la détection des pannes potentielles. Un bon système de monitoring vous alerte en cas de :
- Surcharge des ressources (CPU, mémoire, stockage)
- Défaillance d’un composant matériel
- Erreurs applicatives
Des outils comme Nagios, Zabbix ou Prometheus sont couramment utilisés pour superviser et surveiller les systèmes en temps réel.
Récupération d’Urgence (Disaster Recovery)

Même avec toutes les mesures de prévention, des incidents comme des incendies, inondations ou cyberattaques peuvent se produire. Un plan de récupération d’urgence bien conçu vous permettra de rétablir rapidement vos services.
- Sauvegarde régulière : veillez à sauvegarder toutes vos données critiques fréquemment et à les stocker dans plusieurs lieux géographiques.
- Plan de reprise après sinistre : développez un plan détaillé qui inclut des scénarios pour différents types de catastrophes, des procédures de restauration, et des tests réguliers pour vous assurer que le plan fonctionne.
Garantir la haute disponibilité d’une infrastructure informatique est un processus qui demande une planification, une mise en œuvre précise et une surveillance constante. En intégrant des solutions comme la redondance, le clustering, le load balancing, le monitoring, ainsi qu’un plan de récupération d’urgence solide, vous pouvez significativement réduire les temps d’arrêt et garantir que votre infrastructure reste toujours opérationnelle, même en cas d’incident.